Self-Attention
讲述self-attention我们以sequence labeling任务作为任务来讲解,sequence labeling的任务是输入N个vector并且输出N个label。
典型的例子有输入一个句子,分析每个词汇的词性是什么,比如句子“I saw a saw”,这个句子里saw和saw的词性分别是verb和nonu,如果我们用fully-connected(FC)层来做的话,那么面对同样的输入saw,我们无法得出不同的结果。
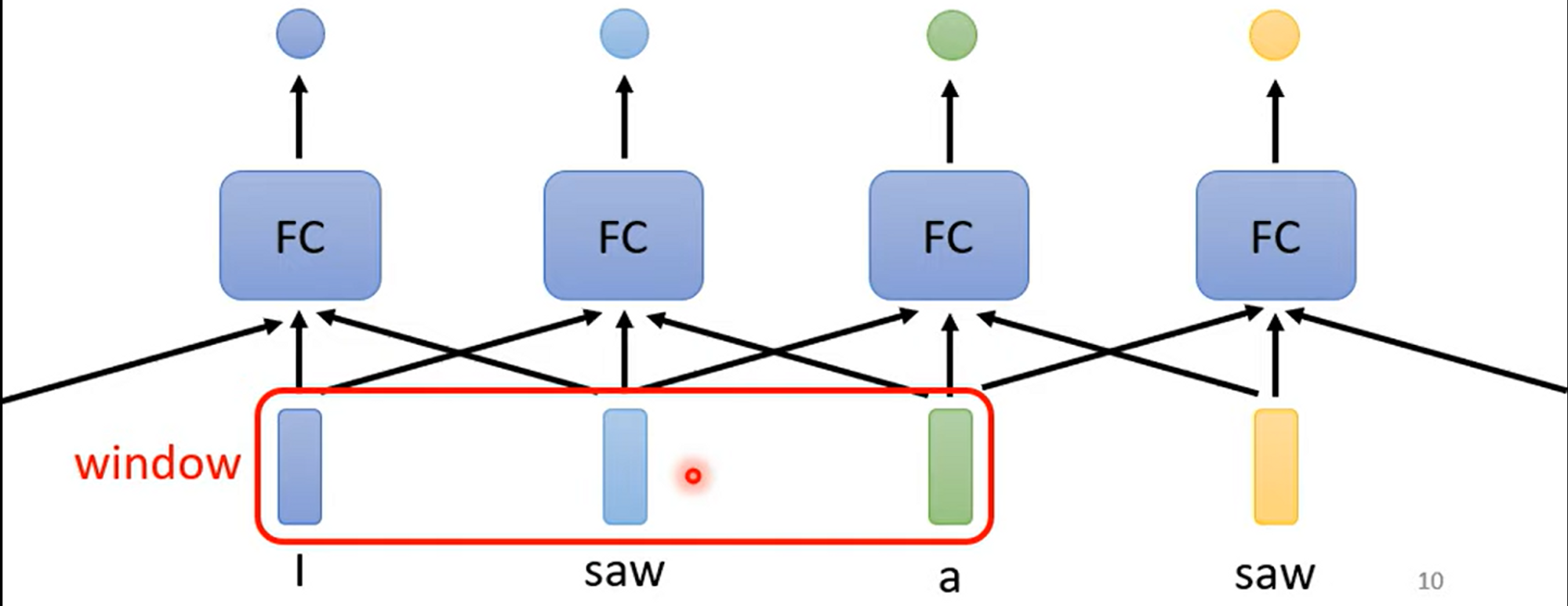
我们的做法可以是对输入加窗,考虑周边邻近的词汇信息,这与信号处理常用的方法类似,但是窗的长度是有限且固定的,而seq的长度是变化的,因此我们在面对这种任务的时候,我们可以借助self-attention层。
Detail
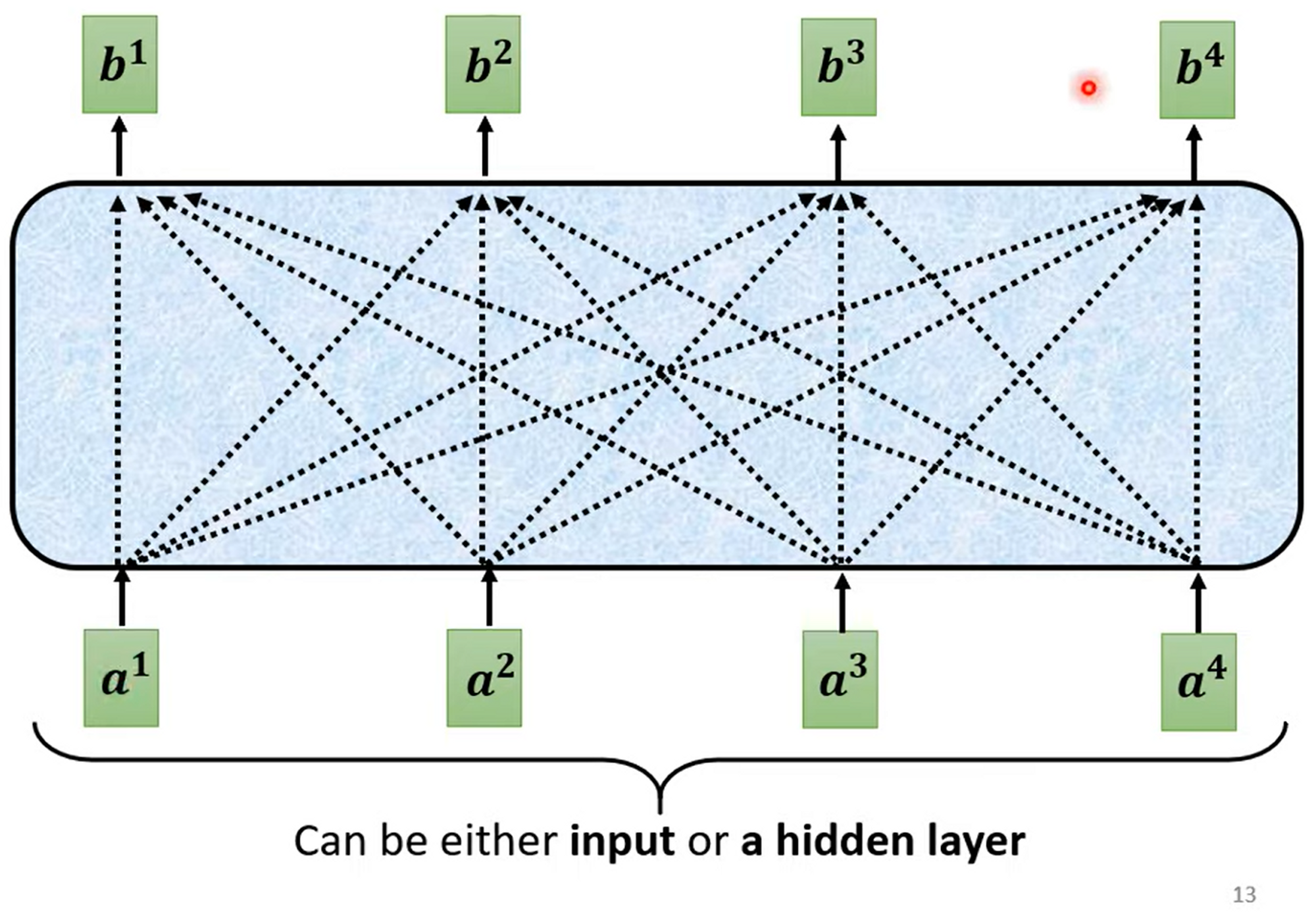
对于Self-attention层,生成的向量是考虑到所有输入向量
Vector Relevance
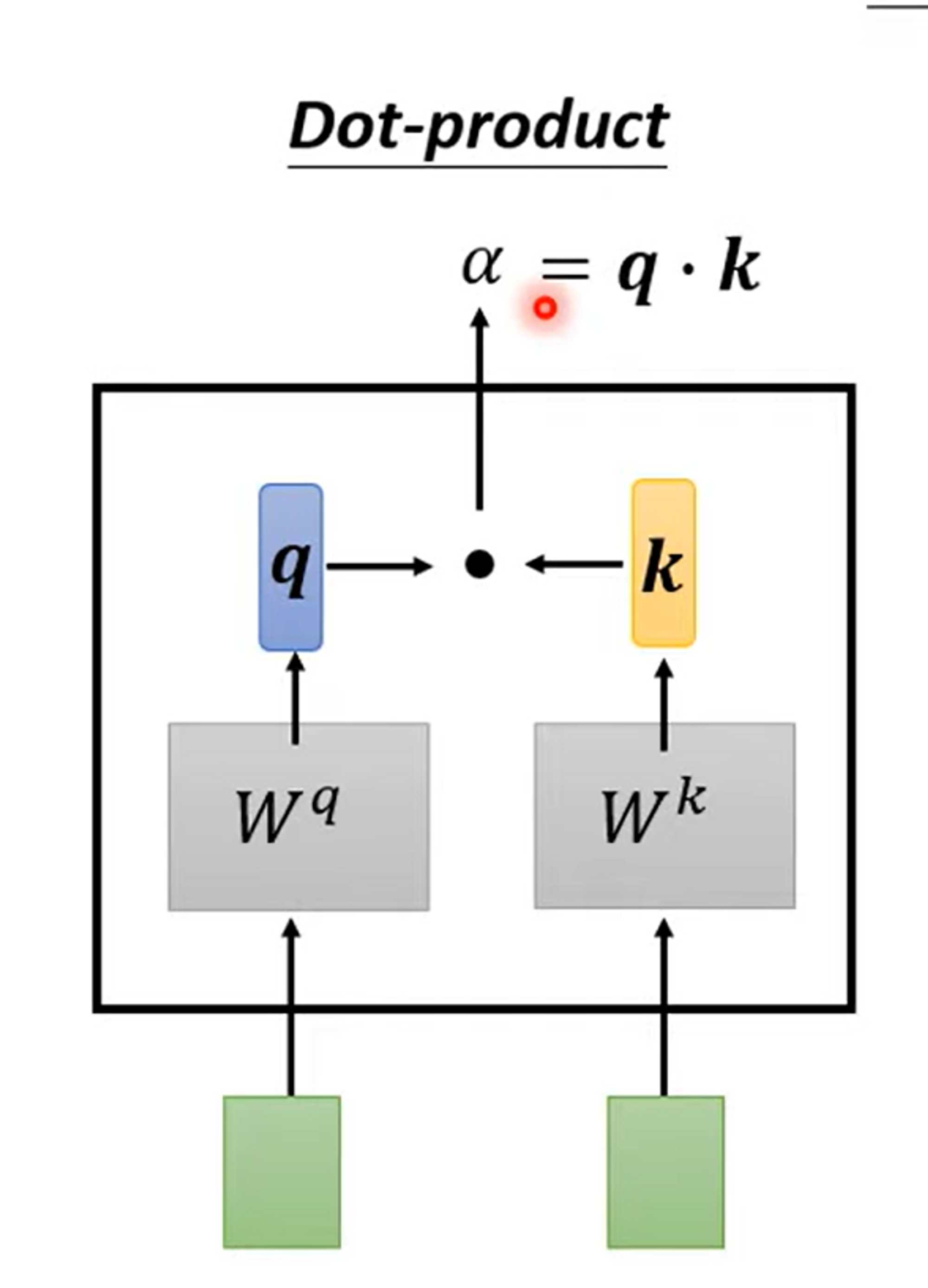
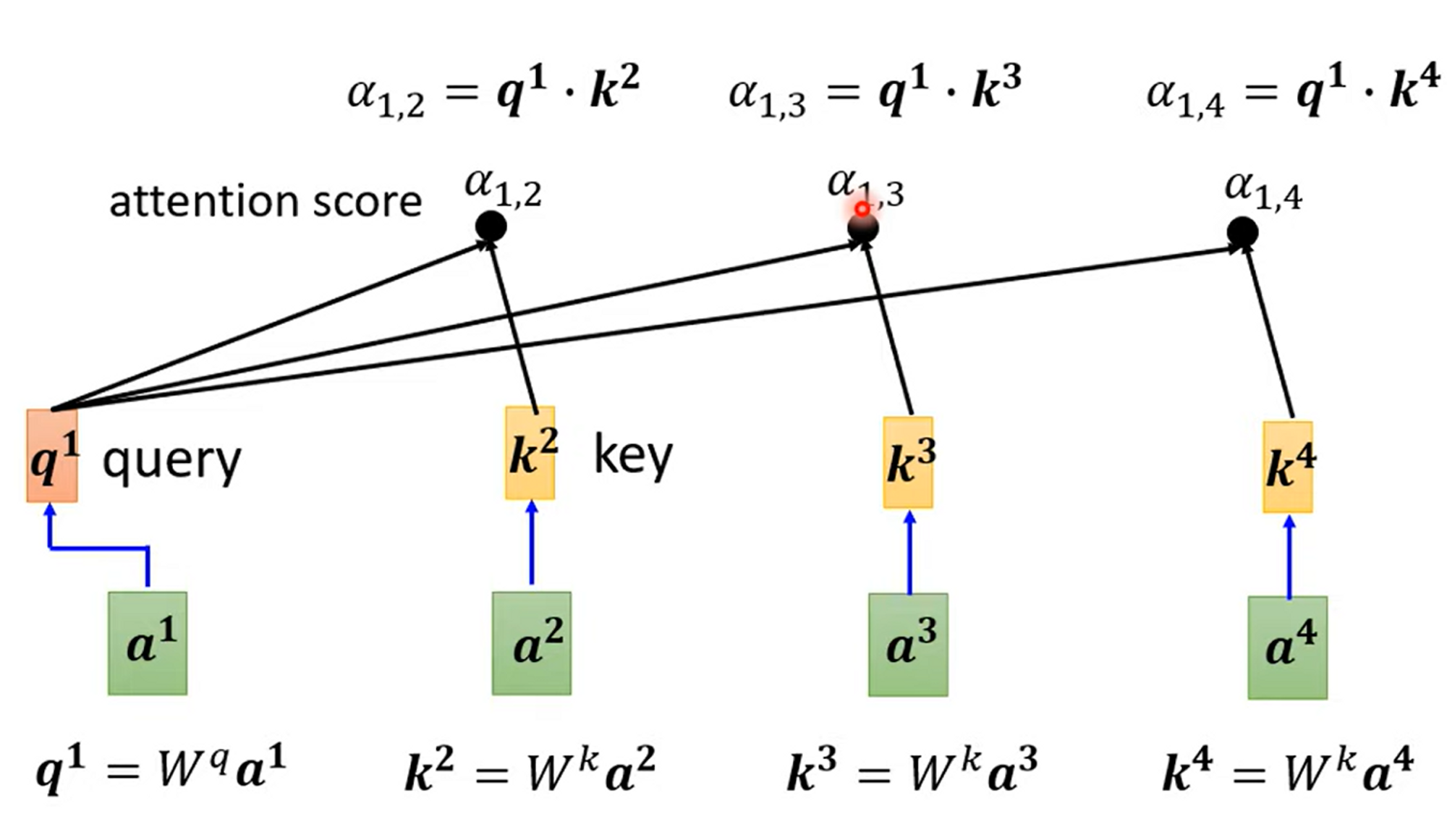
- Step 1. 使用Dot-product 去计算 vector relevance
-
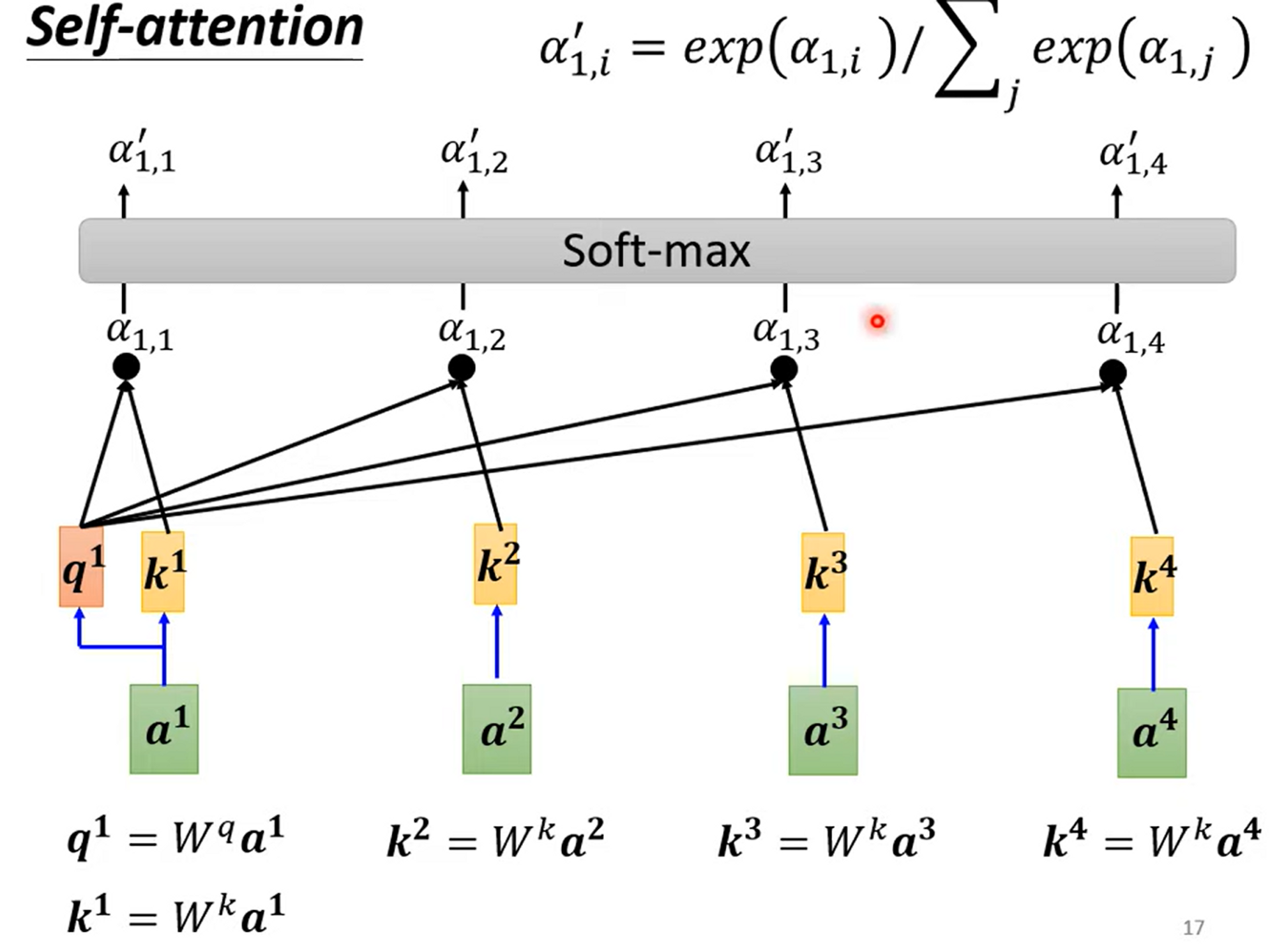
Step 2. Normalizing计算出来的vector relevance
-
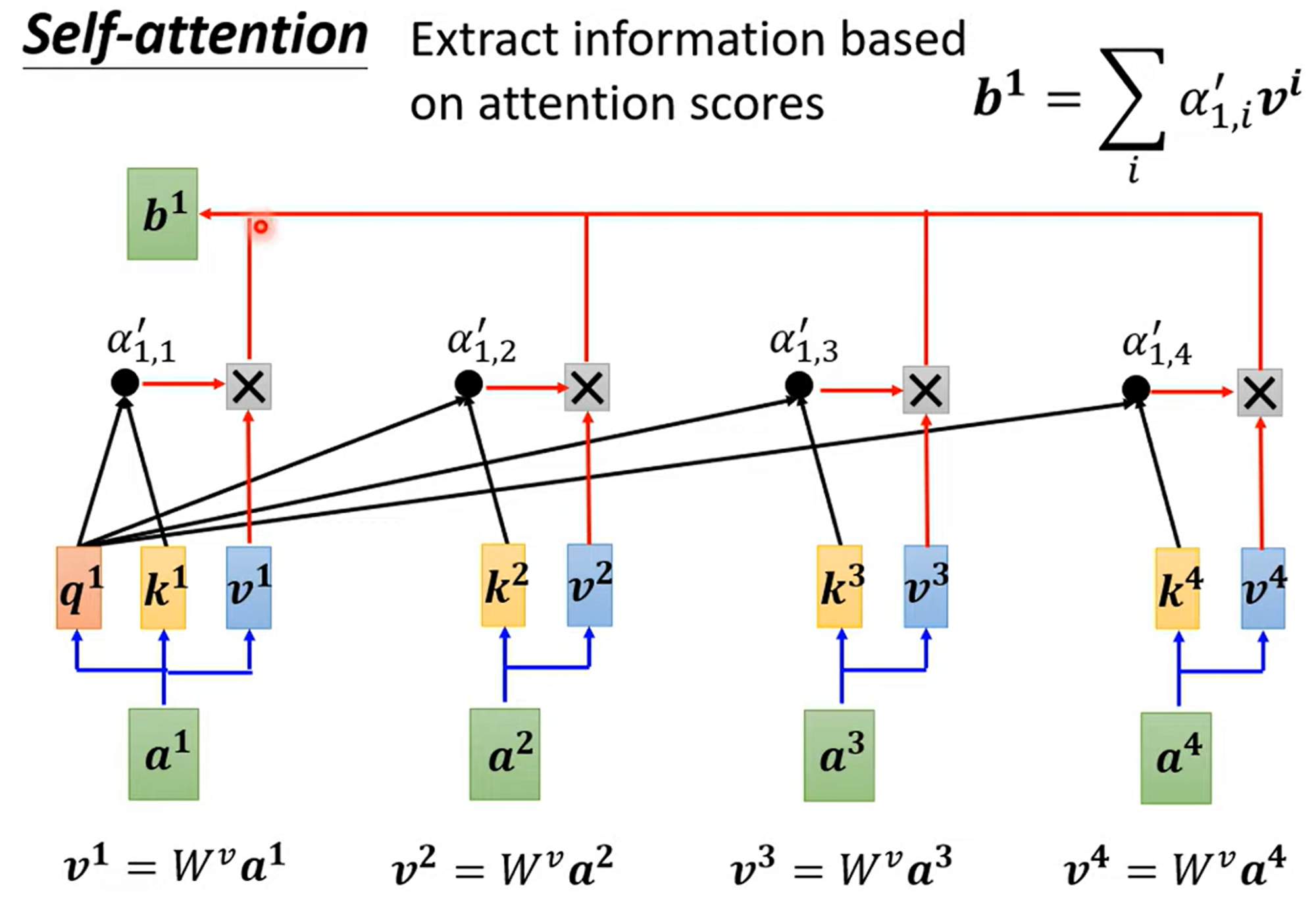
Step 3. 根据vector relevance,也就是attention scores计算最后的输出。这是一个Reweighting Process,一个extract information based on attention scores
Hint
从上面的过程中,可以看出,互相之间的计算没有关系,具有很好的并行性
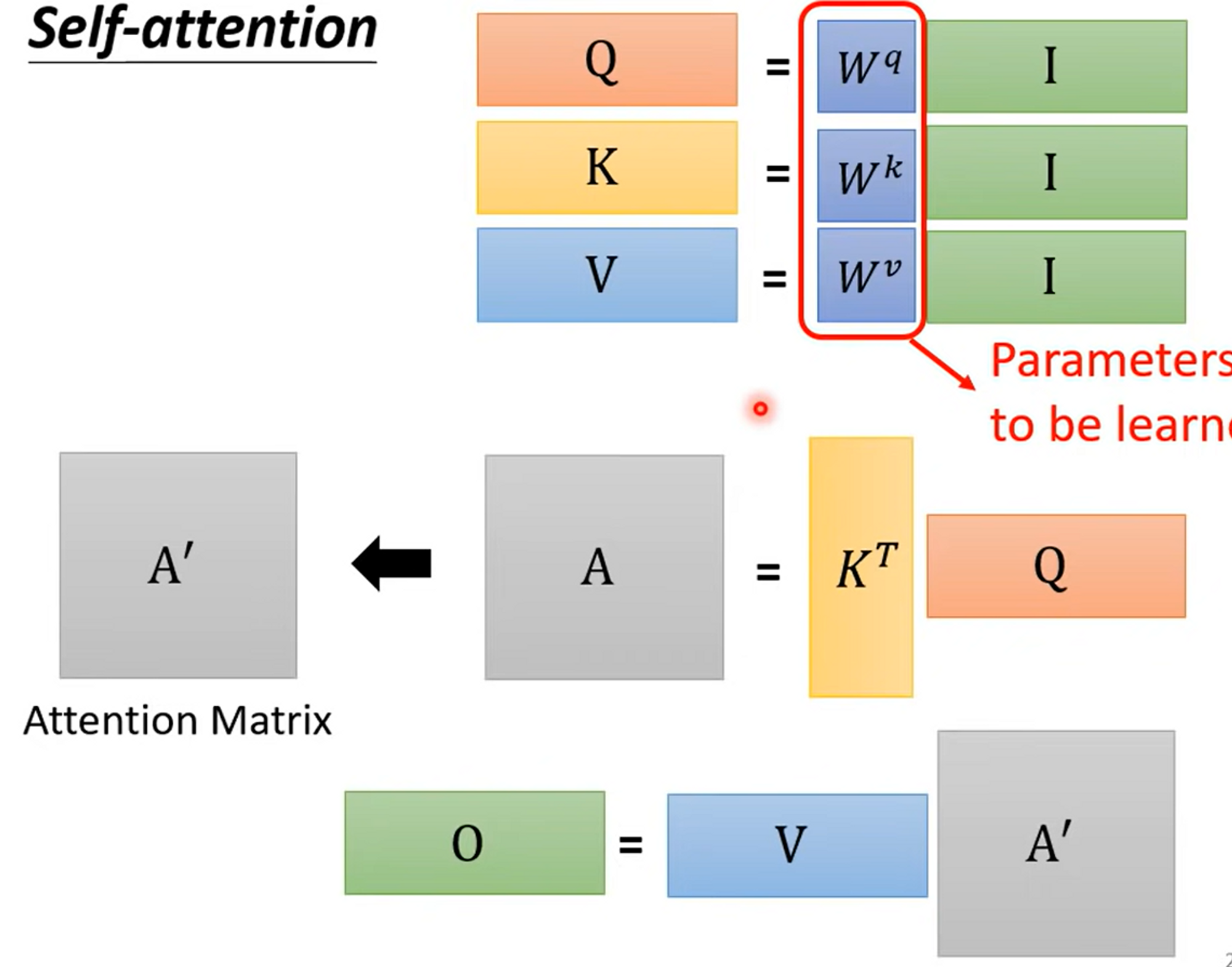
Matrix Detail
So,
As same,
Calculate attention score ,
So,
Finally, calculate output
Positional Encoding
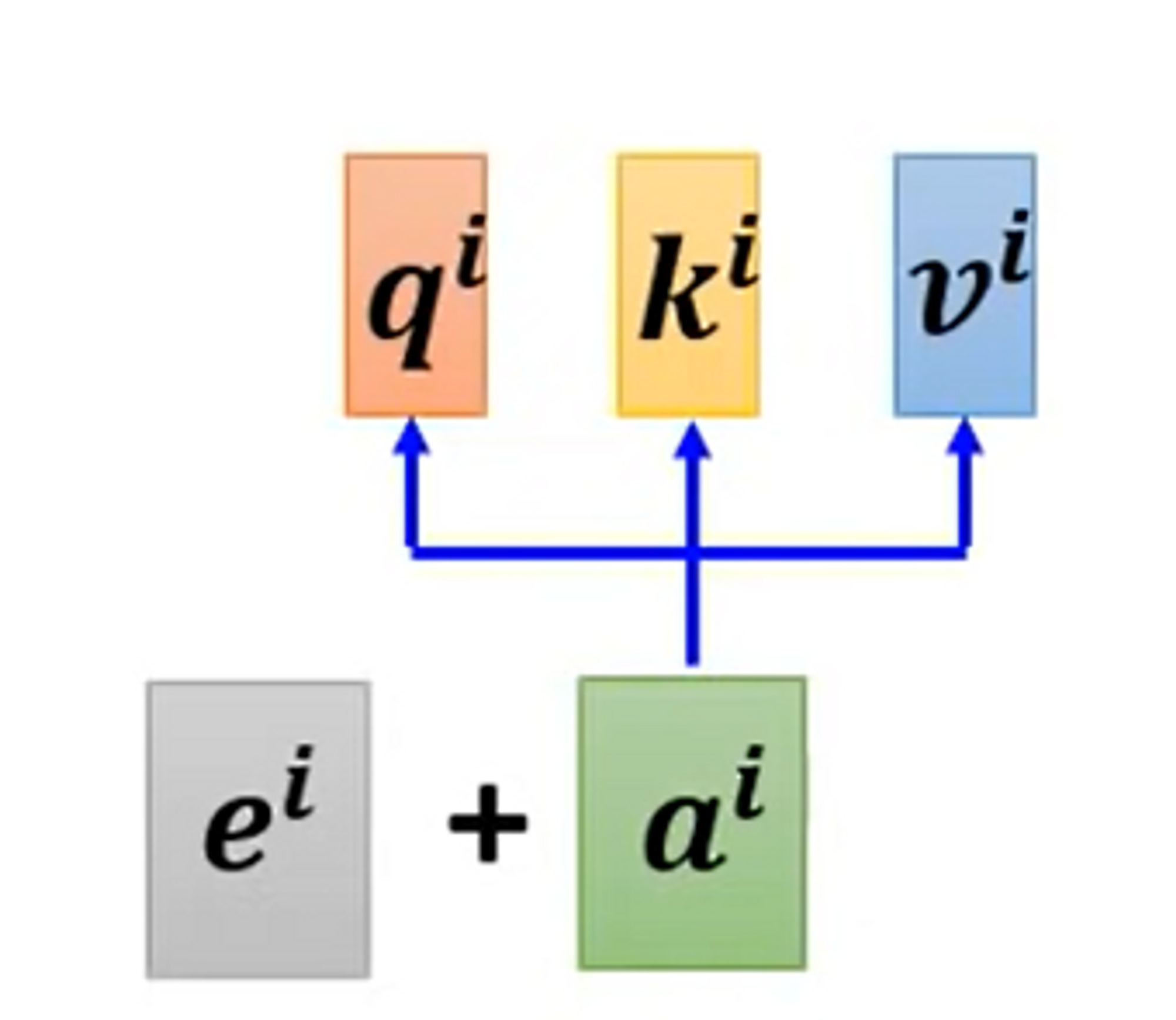
- Each position has a unique positional vector
- hand-crafted
- learned from data
Fun Facts
Self-attention vs. CNN
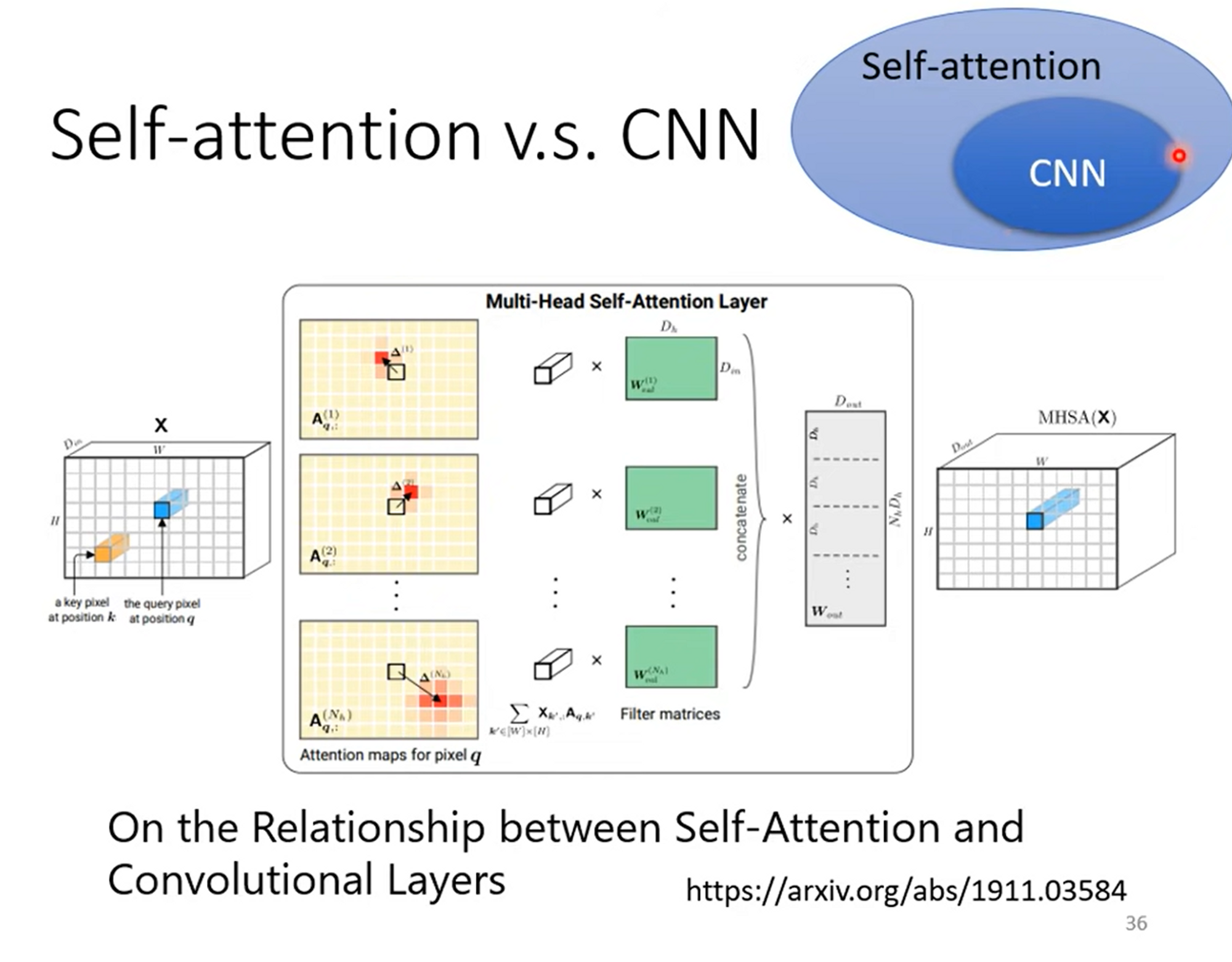
因为transformer有着更大的function set,所以需求更多的数据; 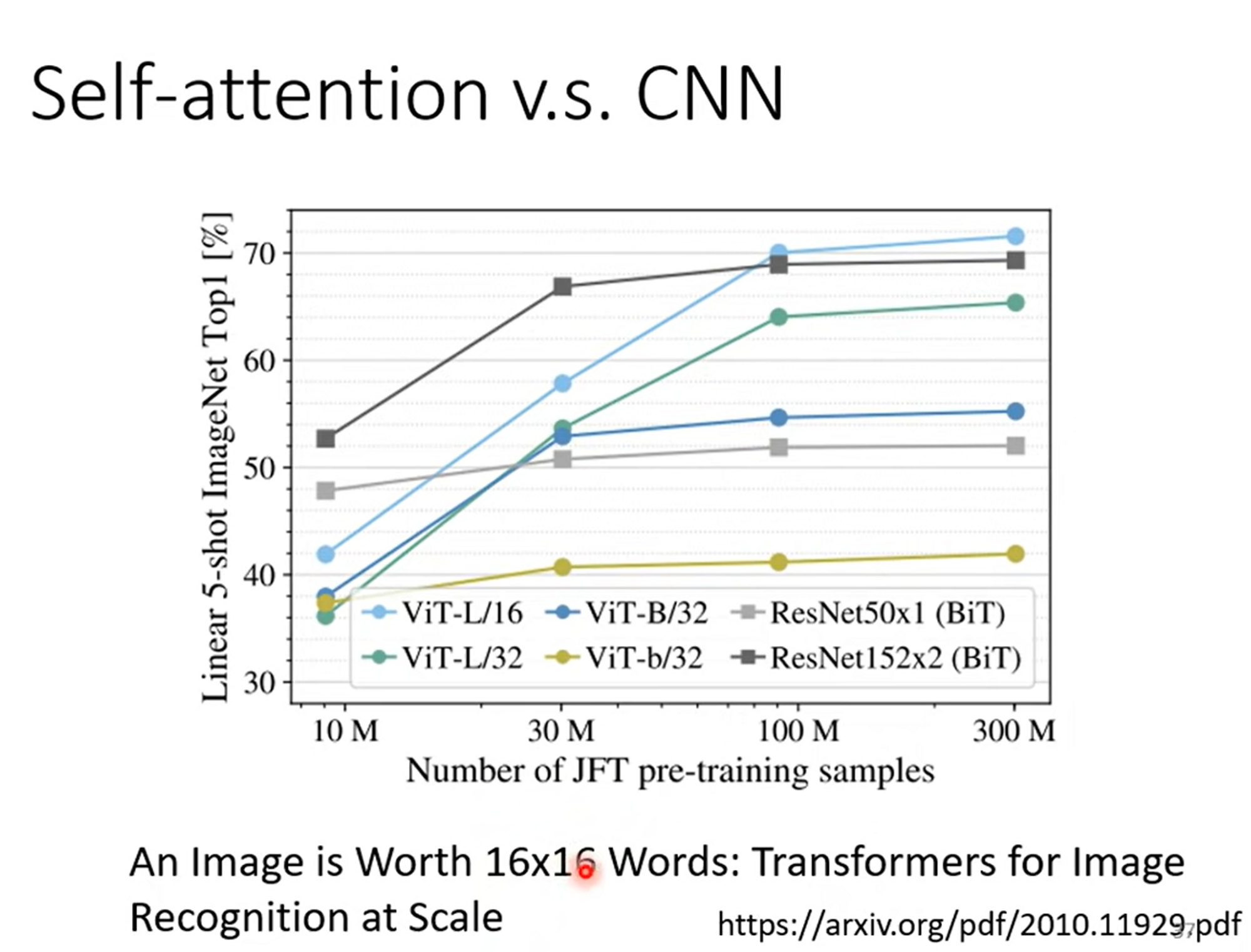
Self-attention vs. RNN
目前,RNN的角色正在被self-attention替代,RNN在long seq的情况下,前面的信息会被逐渐遗忘;同时RNN没有并行性 同样,Self attention有着比RNN更大的function set,在某些情况下,self-attention可以变成RNN
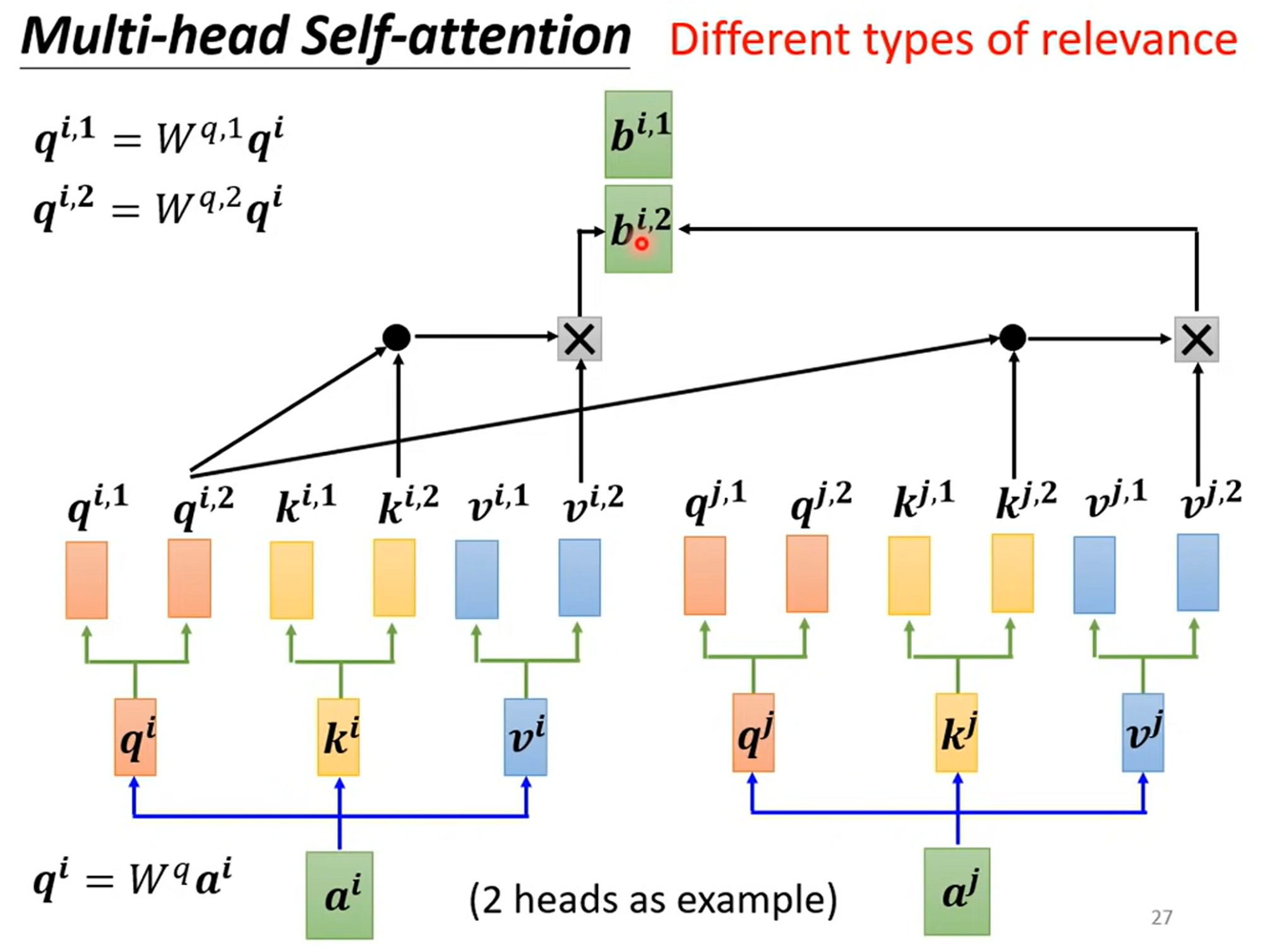
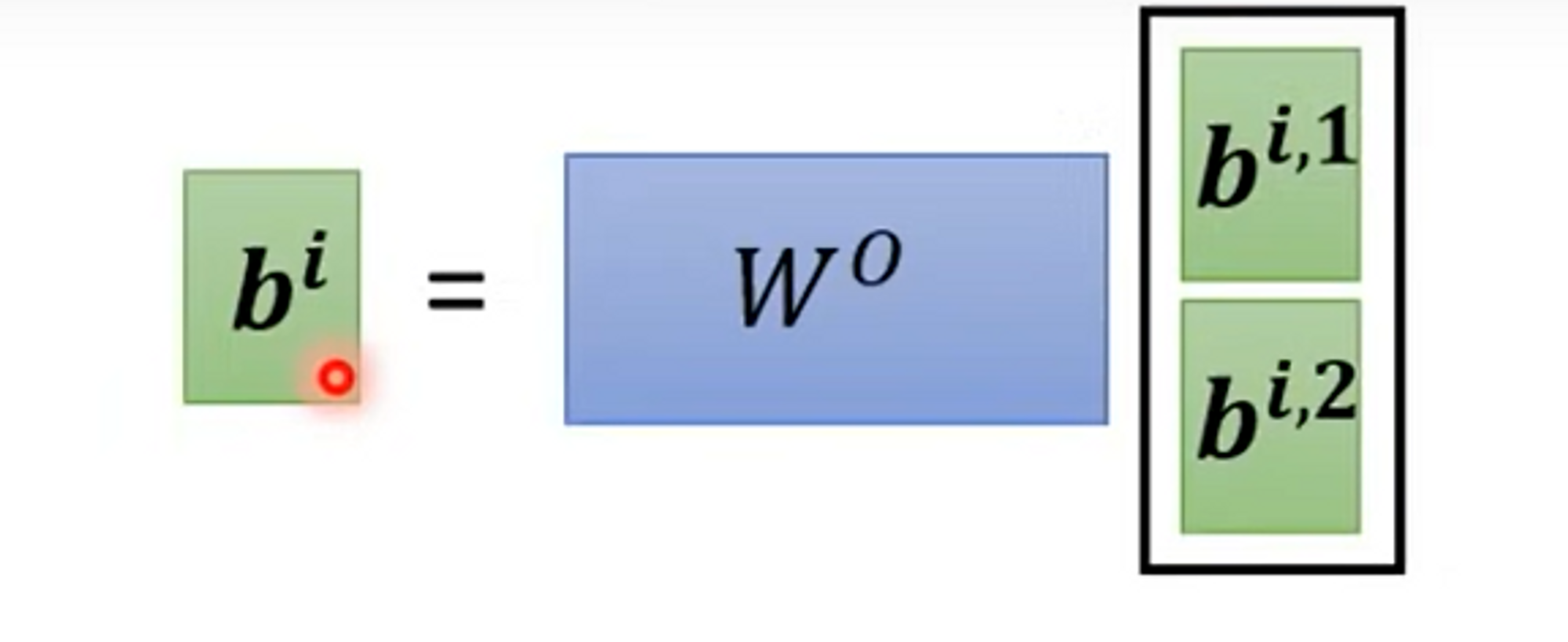
Multi-head Self-attention
Multi-head self attention就是由不同的self attention layer在一起,有不同的,来负责不同种类的relevance