Info
在学习Transformer前,你需要学习 attention
Transformer 是Seq2Seq model,由Encoder和Decoder组成
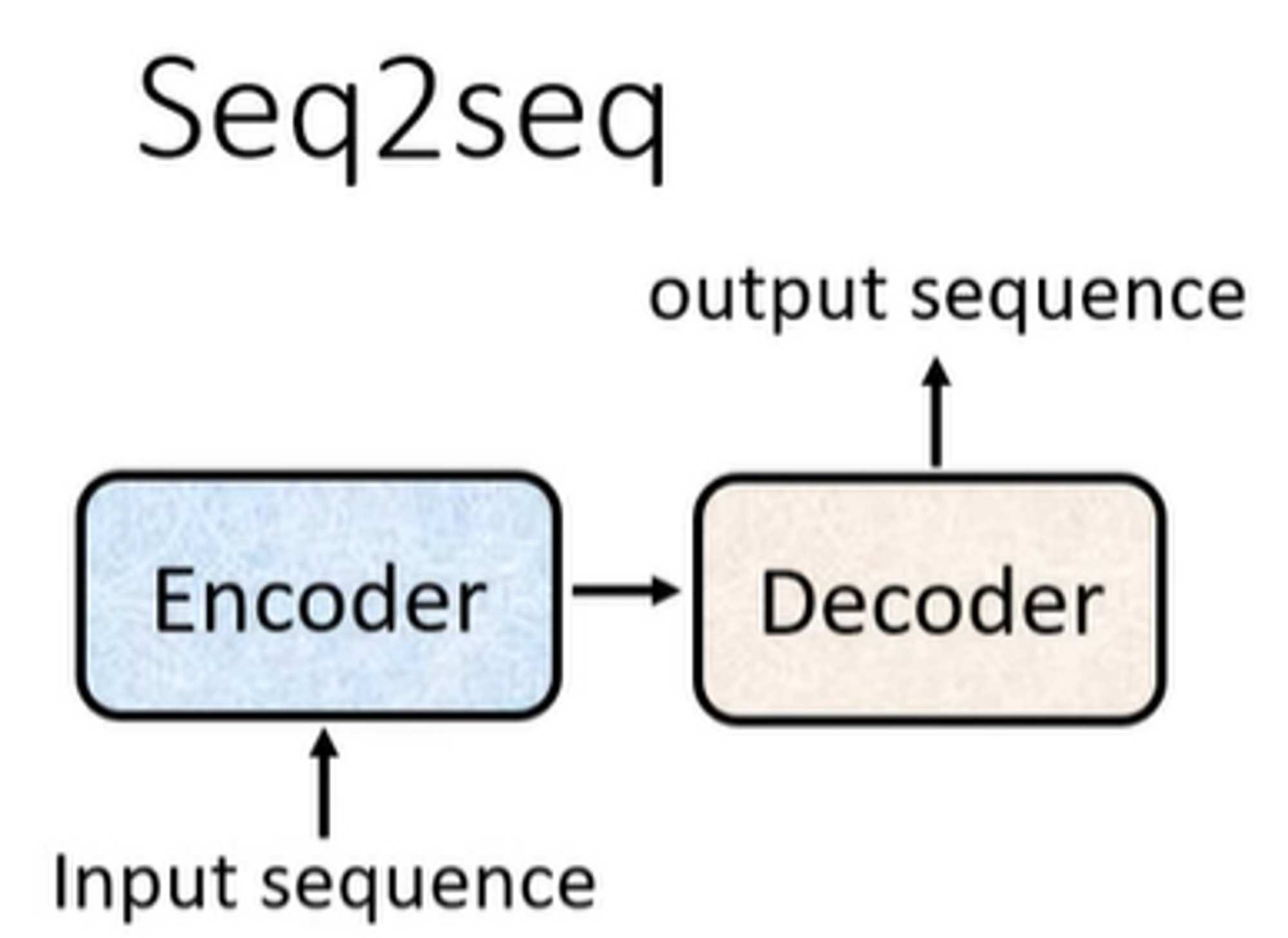
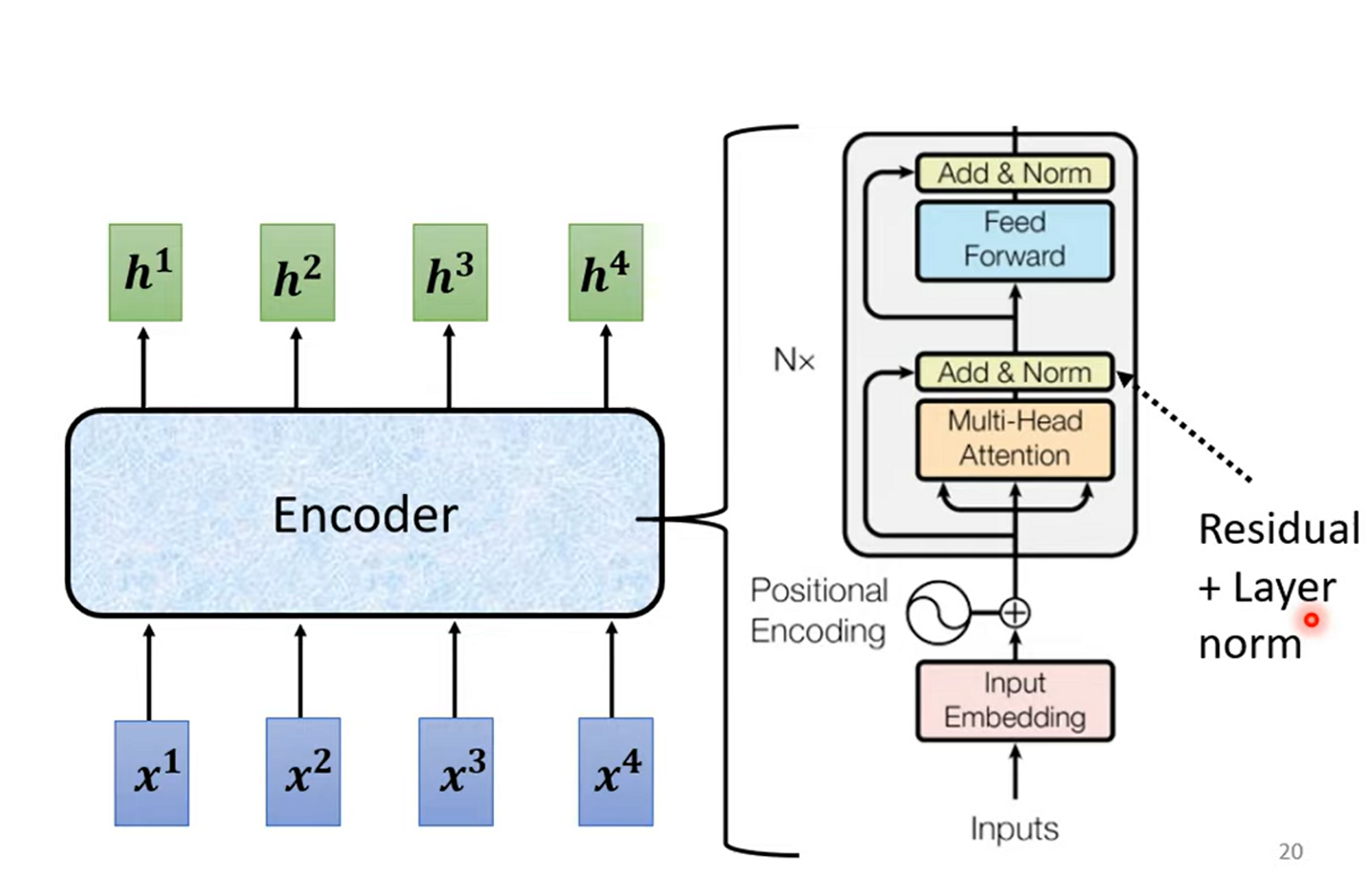
Encoder
这里贴的是原文Encoder的架构
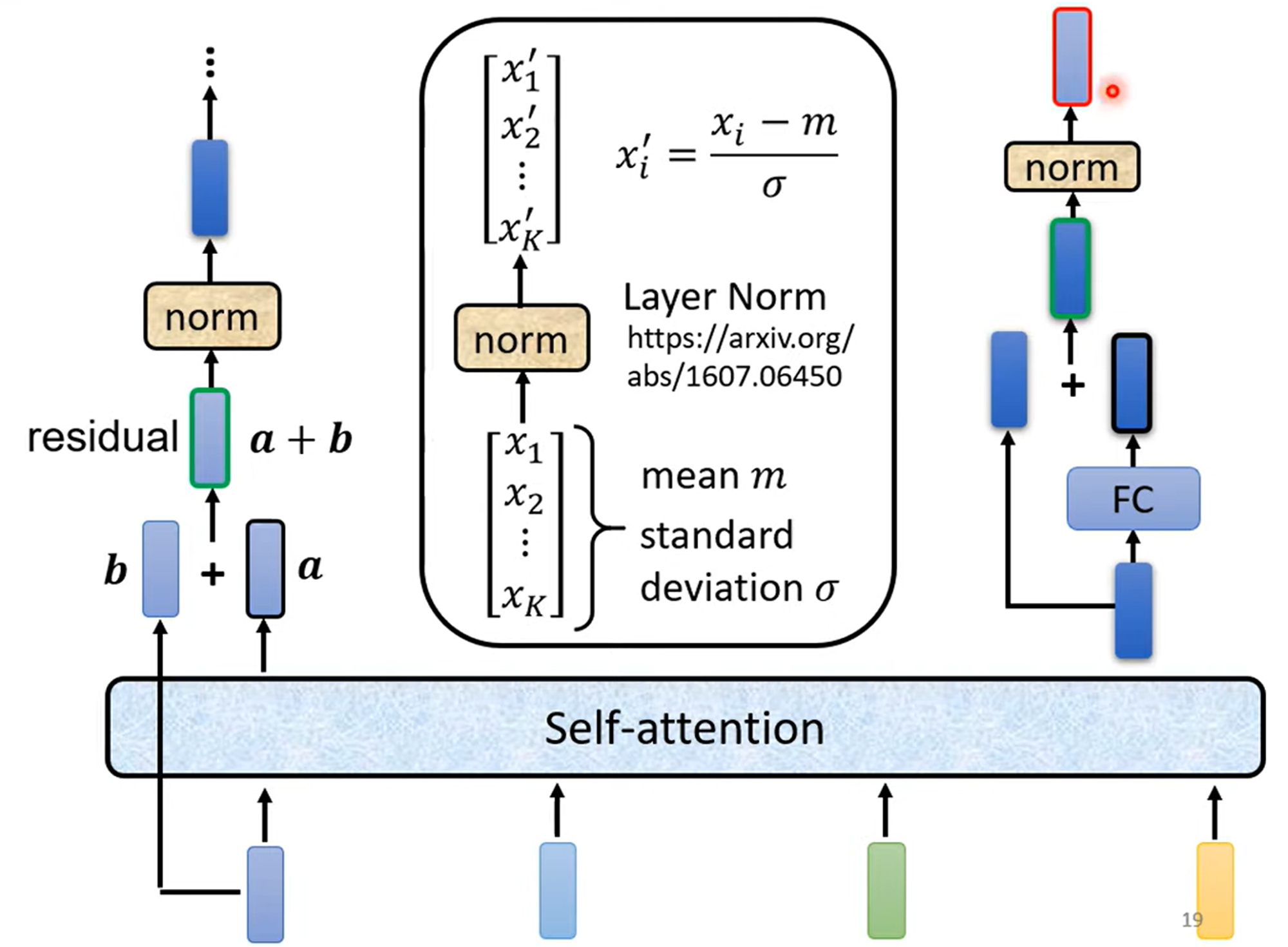
Learn by Animation Demo
2024 VIS poster session 里有一个海报介绍的Transformer Explainer太清晰了,包含word embedding,QKV到attention的计算,dropout, layer normalization … …
通过这个demo可以清晰地理解LLM中Transformer模块地应用
访问:https://poloclub.github.io/transformer-explainer/
