Overview
MNLI-m (Multi-Genre Natural Language Inference - Matched):
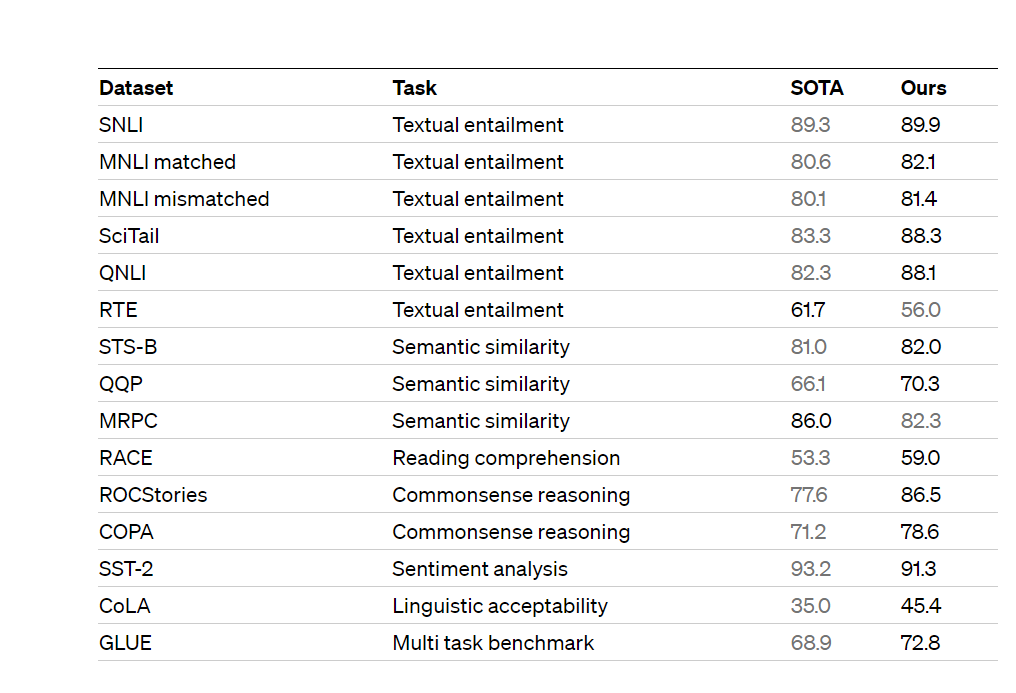
MNLI-m is a benchmark dataset and task for natural language inference (NLI). The goal of NLI is to determine the logical relationship between two given sentences: whether the relationship is “entailment,” “contradiction,” or “neutral.” MNLI-m focuses on matched data, which means the sentences are drawn from the same genres as the sentences in the training set. It is part of the GLUE (General Language Understanding Evaluation) benchmark, which evaluates the performance of models on various natural language understanding tasks.
QNLI (Question Natural Language Inference):
QNLI is another NLI task included in the GLUE benchmark. In this task, the model is given a sentence that is a premise and a sentence that is a question related to the premise. The goal is to determine whether the answer to the question can be inferred from the given premise. The dataset for QNLI is derived from the Stanford Question Answering Dataset (SQuAD).
MRPC (Microsoft Research Paraphrase Corpus):
MRPC is a dataset used for paraphrase identification or semantic equivalence detection. It consists of sentence pairs from various sources that are labeled as either paraphrases or not. The task is to classify whether a given sentence pair expresses the same meaning (paraphrase) or not. MRPC is also part of the GLUE benchmark and helps evaluate models’ ability to understand sentence similarity and equivalence.
SST-2 (Stanford Sentiment Treebank - Binary Sentiment Classification):
SST-2 is a binary sentiment classification task based on the Stanford Sentiment Treebank dataset. The dataset contains sentences from movie reviews labeled as either positive or negative sentiment. The task is to classify a given sentence as expressing a positive or negative sentiment. SST-2 is often used to evaluate the ability of models to understand and classify sentiment in natural language.
SQuAD (Stanford Question Answering Dataset):
SQuAD is a widely known dataset and task for machine reading comprehension. It consists of questions posed by humans on a set of Wikipedia articles, where the answers to the questions are spans of text from the corresponding articles. The goal is to build models that can accurately answer the questions based on the provided context. SQuAD has been instrumental in advancing the field of question answering and evaluating models’ reading comprehension capabilities.
Overall, these tasks and datasets serve as benchmarks for evaluating natural language understanding and processing models. They cover a range of language understanding tasks, including natural language inference, paraphrase identification, sentiment analysis, and machine reading comprehension.