Find a dataset
Find a corpus of text in language you prefer.
- Such as OSCAR
Intuitively, the more data you can get to pretrain on, the better results you will get.
Train a tokenizer
There are something you need take into consideration when train a tokenizer
Tokenization
You can read more detailed post - Tokenization
Tokenization is the process of breaking text into words of sentences. These tokens helps machine to learn context of the text. This helps in interpreting the meaning behind the text. Hence, tokenization is the first and foremost process while working on the text. Once the tokenization is performed on the corpus, the resulted tokens can be used to prepare vocabulary which can be used for further steps to train the model.
Example:
“The city is on the river bank” → “The”, ”city”, ”is”, ”on”, ”the”, ”river”, ”bank”
Here are some typical tokenization:
- Word ( White Space ) Tokenization
- Character Tokenization
- Subword Tokenization (SOTA)
Subword Tokenization can handle OOV(Out Of Vocabulary) problem effectively.
Subword Tokenization Algorithm
- Byte pair encoding (BPE)
- Byte-level byte pair encoding
- WordPiece
- unigram
- SentencePiece
Word embedding
After tokenization, we make our text into token. We also wants to present token in math type. Here we use word embedding technique, converting word to math.
Here are some typical word embedding algorithms:
- Word2Vec
- skip-gram
- continuous bag-of-words (CBOW)
- GloVe (Global Vectors for Word Representations)
- FastText
- ELMo (Embeddings from Language Models)
- BERT (Bidirectional Encoder Representations from Transformers)
- a language model rather than a traditional word embedding algorithm. While BERT does generate word embeddings as a byproduct of its training process, its primary purpose is to learn contextualized representations of words and text segments.
Train a language model from scratch
We need clear the definition of language model.
Language model definition
Simply to say, the language model is a computational model or algorithm that is designed to understand and generate human language. It is a type of artificial intelligence(AI) model that uses statistical and probabilistic techniques to predict and generate sequences of words and sentences.
It captures the statistical relationships between words or characters and builds a probability distribution of the likelihood of a particular word or sequence of words appearing in a given context.
Language model can be used for various NLP tasks, including machine translation, speech recognition, text generation and so on…
As usual, a language model takes a seed input or prompt and uses its learned knowledge of language(model weights) to predict most likely words or characters to follow.
The SOTA of language model today is GPT-4.
Language model algorithm
Classical LM
- n-gram
- N-gram can be used as both a tokenization algorithm and a component of a language model. In my searching experience, n-grams are easier to understand as a language model to predict a likelihood distribution.
- HMMs (Hidden Markov Models)
- RNNs (Recurrent Neural Networks)
Cutting-edge
- GPT (Generative Pre-trained Transformer)
- BERT (Bidirectional Encoder Representations from Transformers)
- T5 (Text-To-Text Transfer Transformer)
- Megatron-LM
Train Method
Different designed models usually have different training methods. Here we take BERT-like model as example.
BERT-Like model
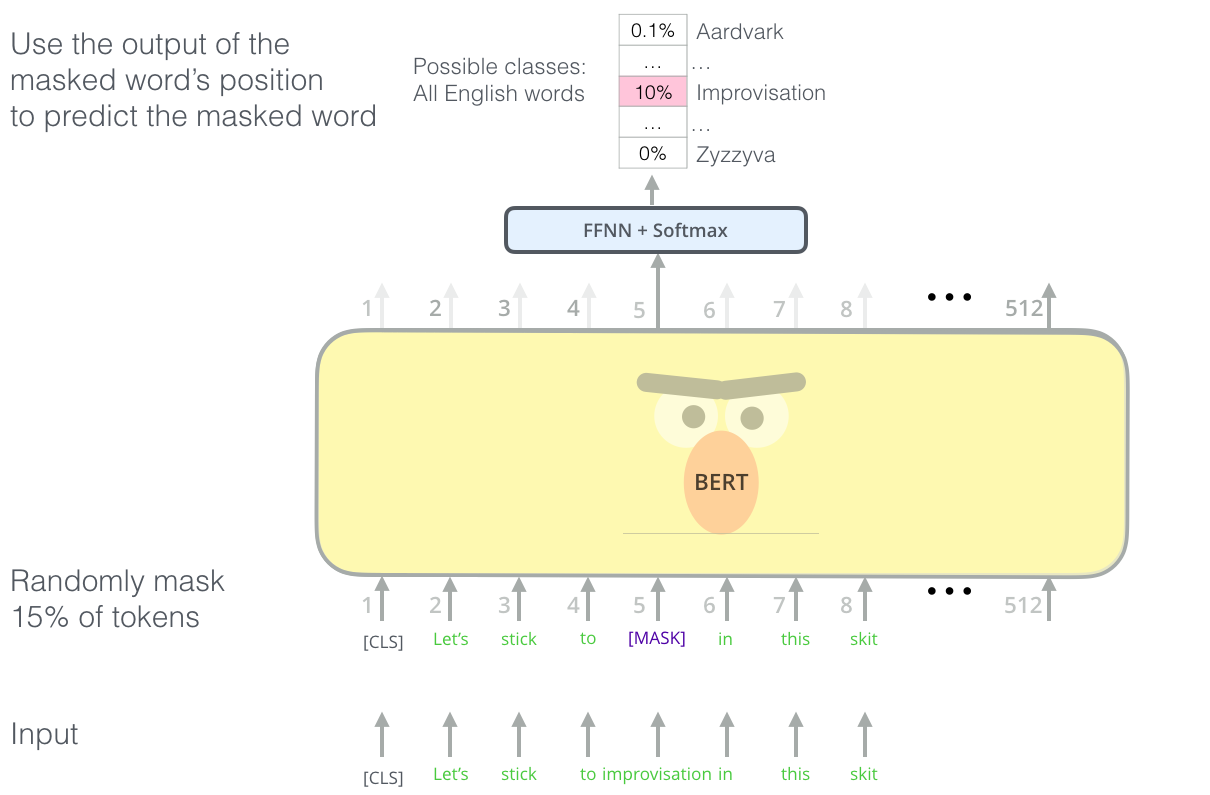
To train BERT-Like model, we’ll train it on a task of Masked Language Modeling(MLM), i.e. the predict how to fill arbitrary tokens that we randomly mask in the dataset.
Also, we’ll train BERT-Like model using Next Sentence Prediction (NSP). MLM teaches BERT to understand relationships between words and NSP teaches BERT to understand long-term dependencies across sentences. In NSP training, give BERT two sentences, A and B, then BERT will determine B is A’s next sentence or not, i.e. outputting IsNextSentence or NotNextSentence
With NSP training, BERT will have better performance.
| Task | MNLI-m (acc) | QNLI (acc) | MRPC (acc) | SST-2 (acc) | SQuAD (f1) |
|---|---|---|---|---|---|
| With NSP | 84.4 | 88.4 | 86.7 | 92.7 | 88.5 |
| Without NSP | 83.9 | 84.9 | 86.5 | 92.6 | 87.9 |
Table source Table metrics explain
Check LM actually trained
Take BERT as example
Aside from looking at the training and eval losses going down, we can check our model using FillMaskPipeline.
This is a method input a masked token (here, <mask>) and return a list of the most probable filled sequences, with their probabilities.
With this method, we can see our LM captures more semantic knowledge or even some sort of (statistical) common sense reasoning.
Fine-tune our LM on a downstream task
Finally, we can fine-tune our LM on a downstream task such as translation, chatbot, text generation and so on.
Different downstream task may need different methods to do fine-tune.