XGBoost is an open-source software library that implements optimized distributed gradient boosting machine learning algorithms under the Gradient Boosting framework.
What you need to know first
What is XGBoost
XGBoost, which stands for Extreme Gradient Boosting, is a scalable, distributed gradient-boosted decision tree (GBDT) machine learning library. It provides parallel tree boosting and is the leading machine learning library for regression, classification, and ranking problems.
It’s vital to an understanding of XGBoost to first grasp the machine learning concepts and algorithms that XGBoost builds upon: supervised machine learning, decision trees, ensemble learning, and gradient boosting.
Here, we need to know ensemble learning and gradient boosting, this two thing I don’t konw before.
What is Ensemble Learning(集成学习)
Ensemble learning is a general meta approach to machine learning that seeks better predictive performance by combining the predictions from multiple models.
The three main classes of ensemble learning methods are bagging, stacking, and boosting.
Bagging
Bagging means Bootstrap aggregation. It’s an ****ensemble learning method that seeks a diverse group of ensemble members by varying the training data.
This typically involves using a single machine learning algorithm, almost always an unpruned decision tree, and training each model on a different sample of the same training dataset. The predictions made by the ensemble members are then combined using simple statistics, such as voting or averaging.
Key to the method is the manner in which each sample of the dataset is prepared to train ensemble members. Each model gets its own unique sample of the dataset.
Bagging adopts the bootstrap distribution for generating different base learners. In other words, it applies bootstrap sampling to obtain the data subsets for training the base learners.
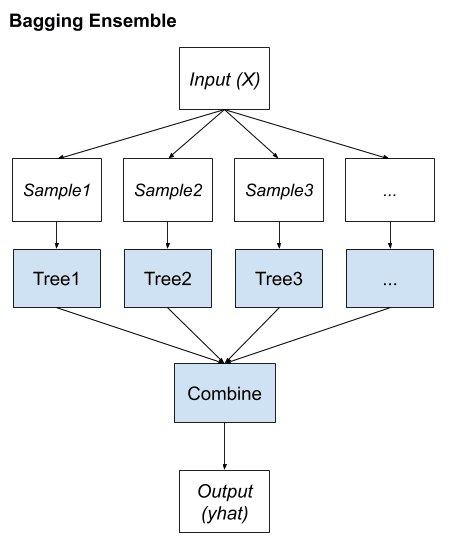
Key word of bagging method:
- Bootstrap Sampling
- Voting or averaging of predictions
- Unpruned decision tree
Random forest is the typical example based on the bagging method.
Stacking
Stacking means Stacked Generalization. It is an ensemble method that seeks a diverse group of members by varying the model types fit on the training data and using a model to combine predictions.
Stacking is a general procedure where a learner is trained to combine the individual learners. Here, the individual learners are called the first-level learners, while the combiner is called the second-level learner, or meta-learner.
Stacking has its own nomenclature where ensemble members are referred to as level-0 models and the model that is used to combine the predictions is referred to as a level-1 model.
The two-level hierarchy of models is the most common approach, although more layers of models can be used. For example, instead of a single level-1 model, we might have 3 or 5 level-1 models and a single level-2 model that combines the predictions of level-1 models in order to make a prediction.
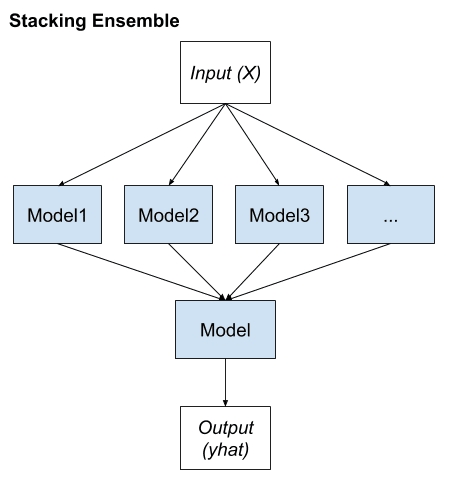
Key words of stacknig method:
- Unchanged training dataset
- Different machine learning algorithms for each ensemble member
- Machine learning model to learn how to best combine predictions
Boosting
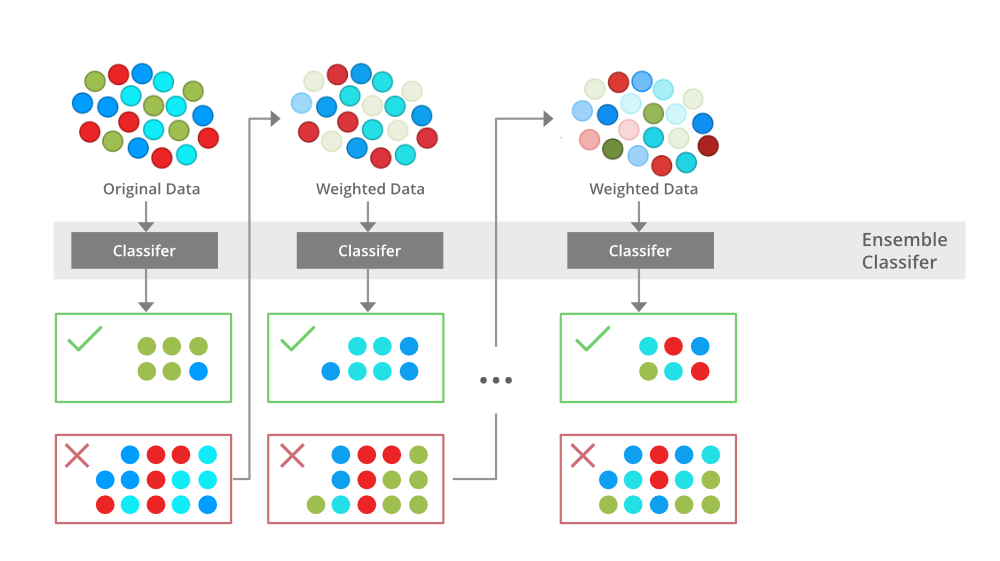
Boosting is an ensemble method that seeks to change the training data to focus attention on examples that previous fit models on the training dataset have gotten wrong.
In boosting, […] the training dataset for each subsequent classifier increasingly focuses on instances misclassified by previously generated classifiers.
The key property of boosting ensembles is the idea of correcting prediction errors. The models are fit and added to the ensemble sequentially such that the second model attempts to correct the predictions of the first model, the third corrects the second model, and so on.
This typically involves the use of very simple decision trees that only make a single or a few decisions, referred to in boosting as weak learners. The predictions of the weak learners are combined using simple voting or averaging, although the contributions are weighed proportional to their performance or capability. The objective is to develop a so-called “strong-learner” from many purpose-built “weak-learners”.
Typically, the training dataset is left unchanged and instead, the learning algorithm is modified to pay more or less attention to specific samples based on whether they have been predicted correctly or incorrectly by previously added ensemble members.
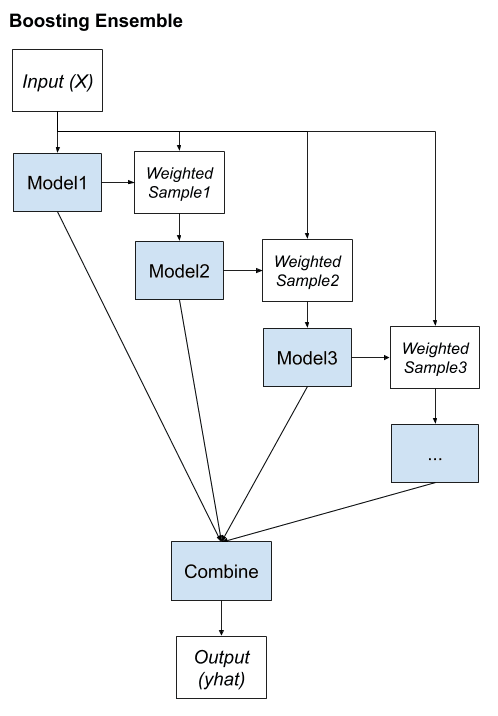
Key words to boosting method:
- Bias training data toward those examples that are hard to predict
- Iteratively add ensemble members to correct predictions of prior models
- Combine predictions using a weighted average of models
Type of boosting:
- Adaptive boosting
- Gradient boosting
- Extreme gradient boosting
Introduction to three main type of boosting method
Adaptive boosting
Adaptive Boosting (AdaBoost) was one of the earliest boosting models developed. It adapts and tries to self-correct in every iteration of the boosting process.
AdaBoost initially gives the same weight to each dataset. Then, it automatically adjusts the weights of the data points after every decision tree. It gives more weight to incorrectly classified items to correct them for the next round. It repeats the process until the residual error, or the difference between actual and predicted values, falls below an acceptable threshold.
You can use AdaBoost with many predictors, and it is typically not as sensitive as other boosting algorithms. This approach does not work well when there is a correlation among features or high data dimensionality. Overall, AdaBoost is a suitable type of boosting for classification problems.
Must check Learning material below to know more detail of this algorithm. 🚧🚧🚧
Gradient boosting
Gradient Boosting (GB) is similar to AdaBoost in that it, too, is a sequential training technique. The difference between AdaBoost and GB is that GB does not give incorrectly classified items more weight. Instead, GB software optimizes the loss function by generating base learners sequentially so that the present base learner is always more effective than the previous one. This method attempts to generate accurate results initially instead of correcting errors throughout the process, like AdaBoost. For this reason, GB software can lead to more accurate results. Gradient Boosting can help with both classification and regression-based problems.
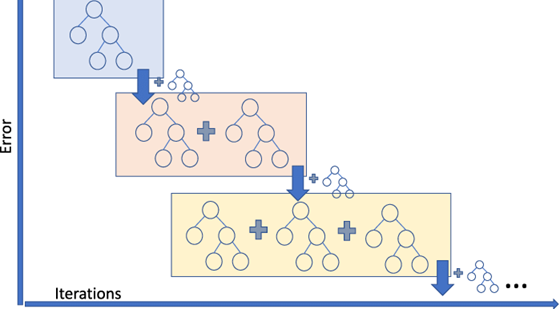
Extreme gradient boosting
Extreme Gradient Boosting (XGBoost) improves gradient boosting for computational speed and scale in several ways. XGBoost uses multiple cores on the CPU so that learning can occur in parallel during training. It is a boosting algorithm that can handle extensive datasets, making it attractive for big data applications. The key features of XGBoost are parallelization, distributed computing, cache optimization, and out-of-core processing.