Quote
When I was learning LSTM, the new deep learning block Transformers dominate the NLP field. However, Transformers don’t decisively outperform LSTMS in time-series-related tasks. The main reason is that LSTMs are more adept at handling local temporal data.
LSTM的设计目标是解决传统RNN面临的长期依赖问题。传统RNN在处理长序列时,难以记住远距离的信息,因为随着时间的推移,梯度在传播过程中逐渐消失或爆炸。这使得传统RNN难以捕捉长期依赖关系,例如在自然语言处理中理解长句子的语义。
LSTM通过使用一种称为门控机制的技术,有效地解决了这个问题。它包含一个称为记忆单元的重要组件,这个单元可以选择性地存储、读取和删除信息。LSTM的关键在于其三个门控单元:输入门、遗忘门和输出门。
-
输入门(Input Gate):决定哪些信息将被更新到记忆单元中。它使用一个Sigmoid激活函数来控制输入的重要性。
-
遗忘门(Forget Gate):决定哪些信息将被从记忆单元中删除。通过使用另一个Sigmoid激活函数和一个逐元素的乘法操作,它决定了上一个记忆状态中的哪些信息保留下来。
-
输出门(Output Gate):决定将哪些信息从记忆单元输出到下一个时间步。这个输出经过一个Sigmoid激活函数和一个Tanh激活函数来进行处理。
这些门控单元允许LSTM选择性地记住或忘记特定的信息,从而使其能够有效地处理长序列。LSTM的网络结构使得信息可以在时间上流动,同时保留对过去信息的长期记忆。
Arch
可以通过比较传统RNN模块和LSTM模块来加深记忆
传统RNN网络:
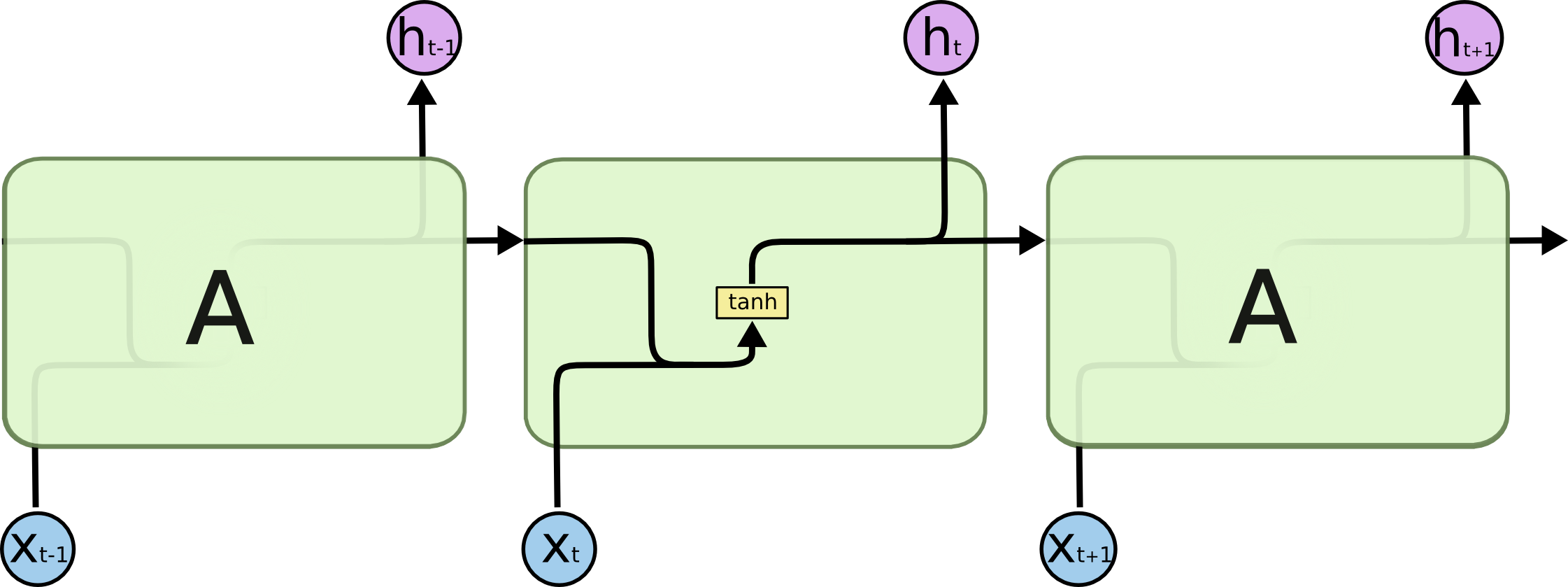
LSTM模块:
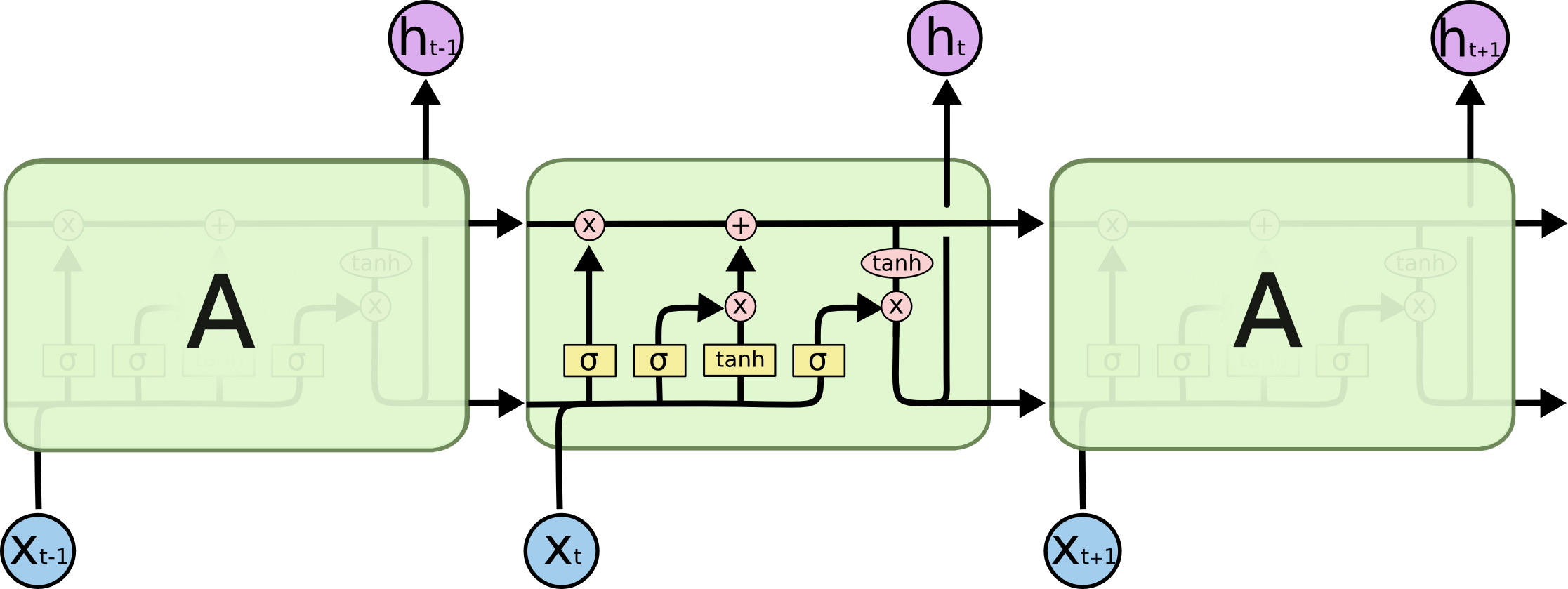

Core idea
LSTM的core idea是cell state, cell state可以被视为一个横贯整个LSTM网络的内部记忆。它类似于传统RNN中的隐藏状态,但相比之下,cell state的设计更加精细,使得LSTM能够更好地捕捉长期依赖关系。
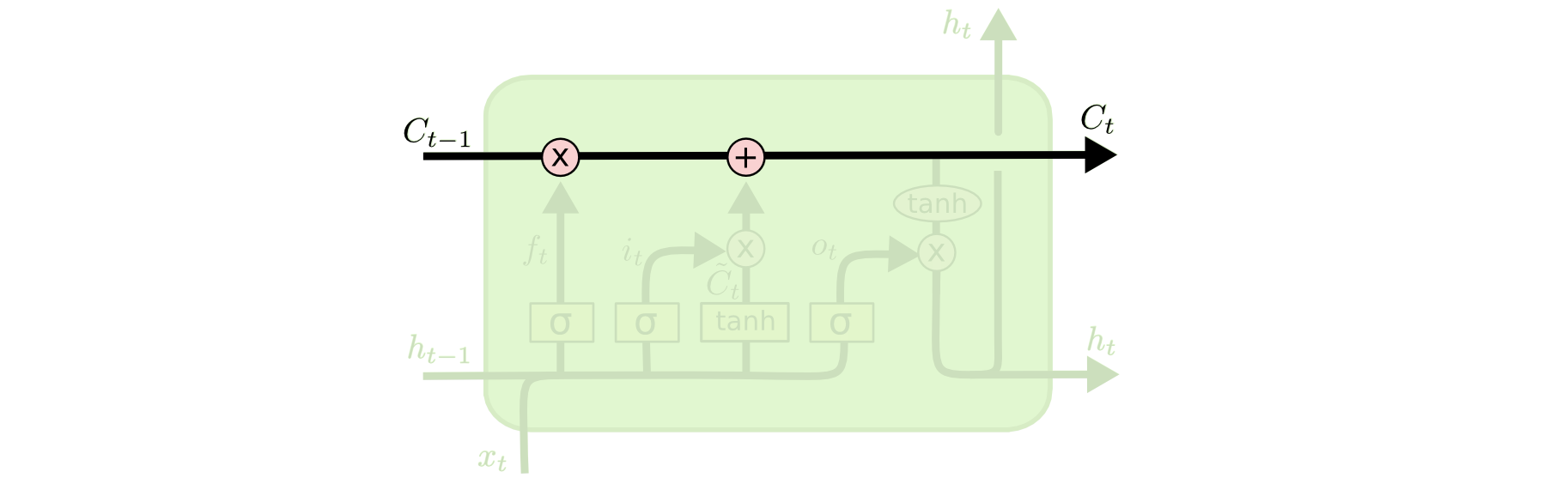
cell state的更新是通过门控单元来控制的。在LSTM中,输入门、遗忘门和输出门共同决定了如何更新细胞状态。
Step-by-Step LSTM Walk Through
Step 1 - Throw away information
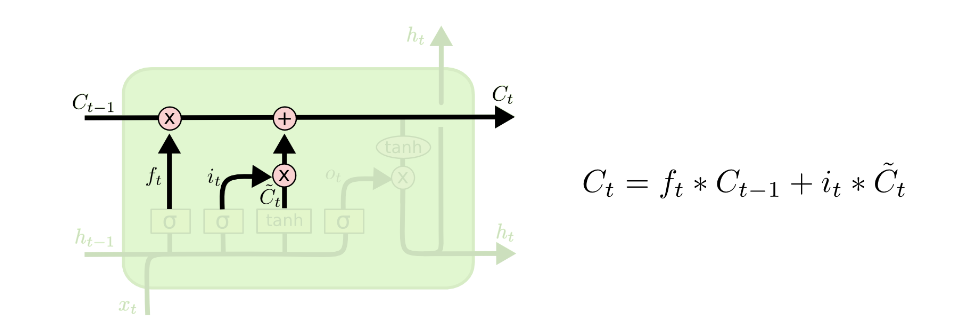
LSTM第一步是throw away information,通过遗忘门(forget gate layer)。
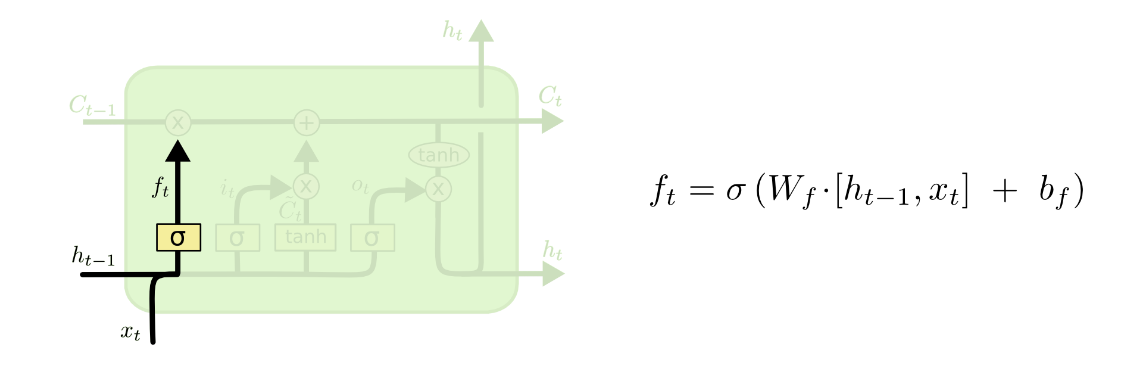
forget gate layer 通过输入和,计算出,范围在(0,1),这个会去乘以cell state 。1代表着“completely keep”,0代表着“completely get rid of this”
一个好的例子,在nlp中,cell state可能包括当前主体的性别,以便可以使用正确的代词。 当我们看到一个新主题时,我们想忘记旧主题的性别。
Step 2 - Decide What information we’re going to store
LSTM第二步在于决定哪些信息要被store在cell state里,这里有两个部分,第一个部分是通过”input gate layer”(输入门),计算。第二个部分通过一个tanh layer来计算新候选值的向量 。这两个部分将会用来update information in cell state
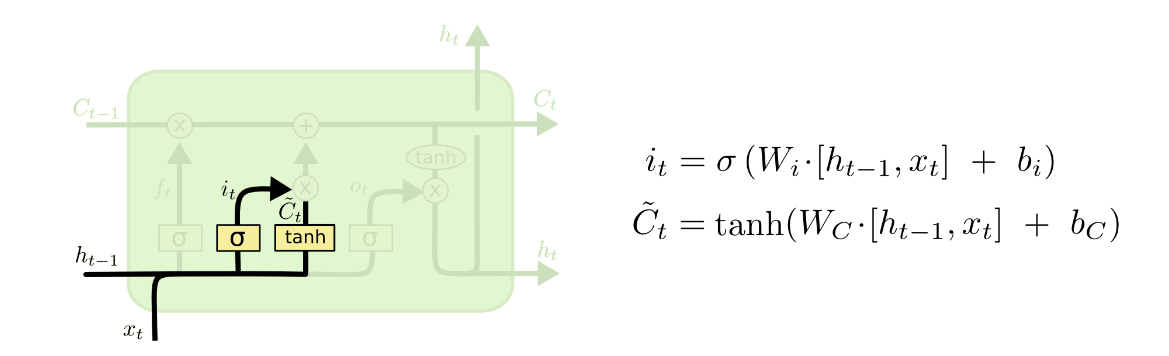
Step 3 - Decide output
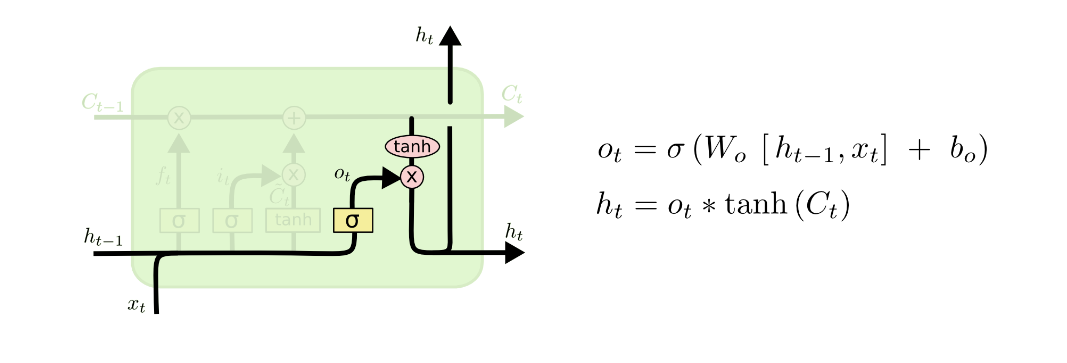
最终的输出回事一个filtered version of cell state,计算如上图。
Variants on LSTM
LSTM有很多变种,这里有列出来一些
Adding “peephole connections”
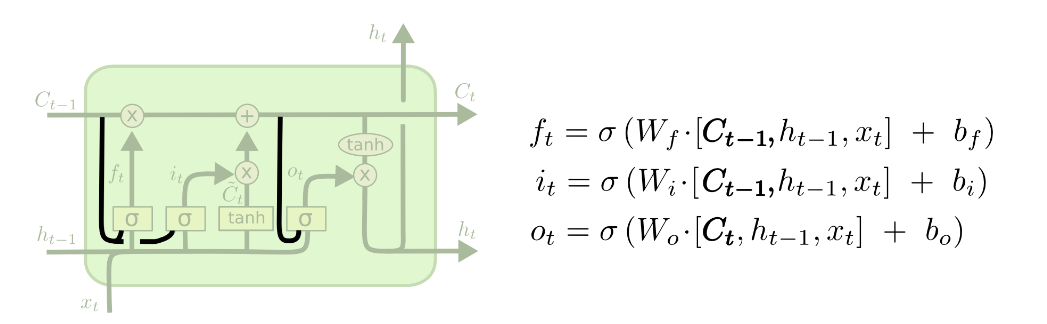
在gate layer的输入中加入cell state,你可以选择在这三个门里的某些加入“peephole connection”(窥视孔连接),某些不加入。
加入窥视孔连接的目的是增强LSTM对细胞状态的建模能力,并更好地捕捉序列中的长期依赖关系。
Use coupled forget and input gates
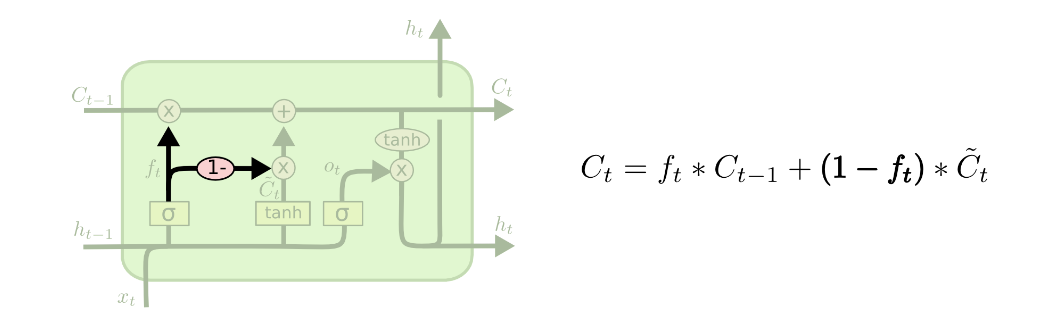
GRU (Gated Recurrent Unit) ⭐⭐⭐
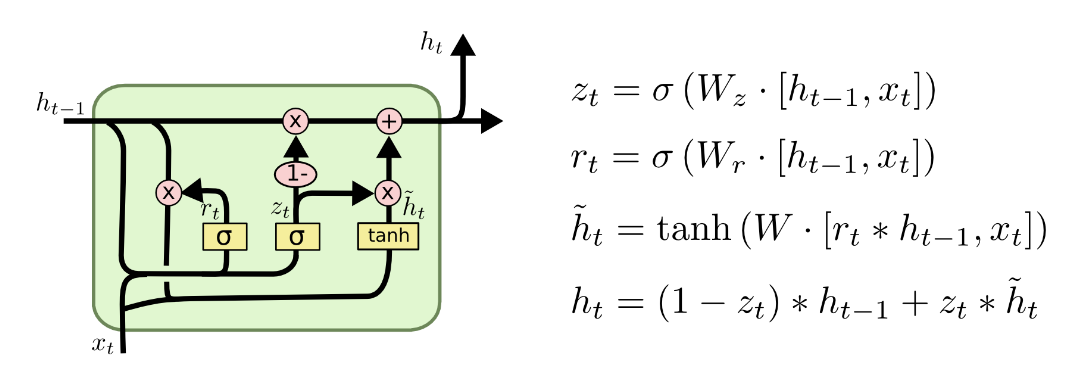
GRU是著名的LSTM变种,值得另起炉灶介绍
Demo code & Pytorch version LSTM graph explain
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
class LSTM(nn.Module):
def __init__(self, input_size, output_size, hidden_size, num_layers):
super(LSTM, self).__init__()
self.input_size = input_size
self.output_size = output_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, input_seq):
# input_seq: (seq_len, batch, input_size)
# lstm_out: (seq_len, batch, hidden_size)
lstm_out, (hidden_state, cell_state) = self.lstm(input_seq)
lstm_out = self.fc(lstm_out)
return lstm_out, hidden_state, cell_state
if __name__ == '__main__':
seq = np.linspace(0, 3801, 3801)
h = torch.randn(1, 1, 64)
c = torch.randn(1, 1, 64)
lstm = LSTM(1, 1, 64, 1)
input = torch.Tensor(seq).view(len(seq), 1, -1)
lstm_out, hidden_state, cell_state = lstm(input)
lstm_out = torch.squeeze(lstm_out)
print(lstm_out.shape)
print(hidden_state.shape)
print(cell_state.shape)Reference
- Understanding LSTM Networks — Colah’s Blog. https://colah.github.io/posts/2015-08-Understanding-LSTMs/. Accessed 22 May 2023.
- Hochreiter, Sepp, and Jürgen Schmidhuber. “Long Short-Term Memory.” Neural Computation, vol. 9, no. 8, Nov. 1997, pp. 1735–80. DOI.org (Crossref), https://doi.org/10.1162/neco.1997.9.8.1735.
- Recurrent Nets That Time and Count. https://ieeexplore.ieee.org/document/861302/. Accessed 22 May 2023.