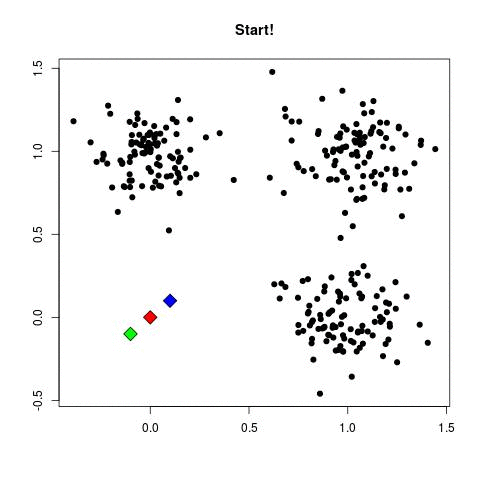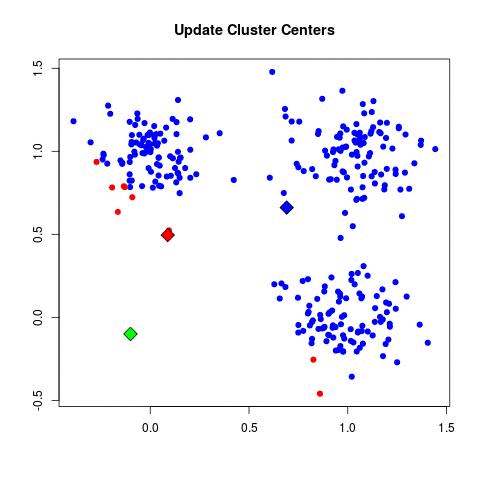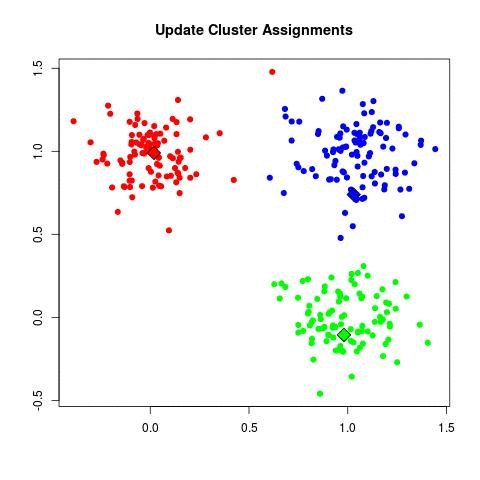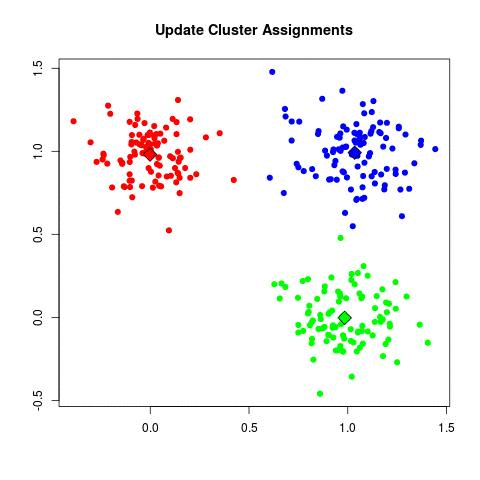
Step by Step
Our algorithm works as follows, assuming we have inputs and value of
- Step 1 - Pick random points as cluster centers called centroids.
- Step 2 - Assign each to nearest cluster by calculating its distance to each centroid.
- Step 3 - Find new cluster center by taking the average of the assigned points.
- Step 4 - Repeat Step 2 and 3 until none of the cluster assignments change.
Implementation
Core code
Distance calculation:
# Euclidean Distance Caculator
def dist(a, b, ax=1):
return np.linalg.norm(a - b, axis=ax)Generate Random Clustering center at first
# Number of clusters
k = 3
# X coordinates of random centroids
C_x = np.random.randint(0, np.max(X)-20, size=k)
# Y coordinates of random centroids
C_y = np.random.randint(0, np.max(X)-20, size=k)
C = np.array(list(zip(C_x, C_y)), dtype=np.float32)
print(C)Calculate dis and tag point, then update every tag’s new center
# To store the value of centroids when it updates
C_old = np.zeros(C.shape)
# Cluster Lables(0, 1, 2)
clusters = np.zeros(len(X))
# Error func. - Distance between new centroids and old centroids
error = dist(C, C_old, None)
# Loop will run till the error becomes zero
while error != 0:
# Assigning each value to its closest cluster
for i in range(len(X)):
distances = dist(X[i], C)
cluster = np.argmin(distances)
clusters[i] = cluster
# Storing the old centroid values
C_old = deepcopy(C)
# Finding the new centroids by taking the average value
for i in range(k):
points = [X[j] for j in range(len(X)) if clusters[j] == i]
C[i] = np.mean(points, axis=0)
error = dist(C, C_old, None)Simple approach by scikit-learn
from sklearn.cluster import KMeans
# Number of clusters
kmeans = KMeans(n_clusters=3)
# Fitting the input data
kmeans = kmeans.fit(X)
# Getting the cluster labels
labels = kmeans.predict(X)
# Centroid values
centroids = kmeans.cluster_centers_
# Comparing with scikit-learn centroids
print(C) # From Scratch
print(centroids) # From sci-kit learnApplication
8bit style
Read image and use k-means to do clustering for pixel value. Make pic to 8bit color style.

import cv2
import numpy as np
import matplotlib.pyplot as plt
from tkinter import Tk, filedialog
from mpl_toolkits.mplot3d import Axes3D
from sklearn.cluster import KMeans
# Create a Tkinter root window
root = Tk()
root.withdraw()
# Open a file explorer dialog to select an image file
file_path = filedialog.askopenfilename()
# Read the selected image using cv2
image = cv2.imread(file_path)
# Convert the image to RGB color space
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Get the dimensions of the image
height, width, _ = image_rgb.shape
# Reshape the image to a 2D array of pixels, one is pixel number, one is pixel channel
pixels = image_rgb.reshape((height * width, 3))
# Create an empty dataset
dataset = []
# Iterate over each pixel and store the RGB values as a vector in the dataset
for pixel in pixels:
dataset.append(pixel)
# Convert the dataset to a NumPy array
dataset = np.array(dataset)
# Get the RGB values from the dataset
red = dataset[:, 0]
green = dataset[:, 1]
blue = dataset[:, 2]
# plot show
'''
# Plot the histograms
plt.figure(figsize=(10, 6))
plt.hist(red, bins=256, color='red', alpha=0.5, label='Red')
plt.hist(green, bins=256, color='green', alpha=0.5, label='Green')
plt.hist(blue, bins=256, color='blue', alpha=0.5, label='Blue')
plt.title('RGB Value Histogram')
plt.xlabel('RGB Value')
plt.ylabel('Frequency')
plt.legend()
plt.show()
# Plot the 3D scatter graph
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
ax.scatter(red, green, blue, c='#000000', s=1)
ax.set_xlabel('Red')
ax.set_ylabel('Green')
ax.set_zlabel('Blue')
ax.set_title('RGB Scatter Plot')
plt.show()
'''
# Perform k-means clustering
num_clusters = 3 # Specify the desired number of clusters
kmeans = KMeans(n_clusters=num_clusters, n_init='auto', random_state=42)
labels = kmeans.fit_predict(dataset)
# Show K-means Clustering result
'''
# Plot the scatter plot for each iteration of the k-means algorithm
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
for i in range(num_clusters):
cluster_points = dataset[labels == i]
ax.scatter(cluster_points[:, 0], cluster_points[:, 1], cluster_points[:, 2], s=1)
ax.set_xlabel('Red')
ax.set_ylabel('Green')
ax.set_zlabel('Blue')
ax.set_title('RGB Scatter Plot - K-Means Clustering')
plt.show()
'''
center_values = kmeans.cluster_centers_.astype(int)
for i in range(num_clusters):
dataset[labels == i] = center_values[i]
# Reshape the pixels array back into an image with the original dimensions and convert it to BGR color space
reshaped_image = dataset.reshape((height, width, 3))
reshaped_image_bgr = cv2.cvtColor(reshaped_image.astype(np.uint8), cv2.COLOR_RGB2BGR)
# Display the image using matplotlib
plt.imshow(reshaped_image)
plt.show()
# Opencv store image
cv2.imwrite('./color8bit_style.jpg', reshaped_image_bgr)